ここで学習すること
教師あり学習の基本であるホールドアウト法を学習します。
ホールドアウト法をPythonで実行するためのtrain_test_splitでデータを訓練データとテストデータに分割する方法を学習します。クロスバリデーションにて少ないデータでも精度を上げる手法を学習します。
教師あり学習では訓練データとテストデータの2つが必要です。訓練データで学習し、テストデータで作成したモデルの精度を評価します。この手法をホールドアウト法といいます。
訓練データ、テストデータの比率は8:2くらいとします。データ数は50個以上必要とされています。
train_test_splitでデータを訓練データとテストデータに分割する
pythonではscikit-learnというライブラリを使います。このライブラリ内のtrain_test_split関数でデータを訓練用データとテストデータへ分割します。ここではデータの分割までを解説します。
scikit-learnのデータセットを読み込みます
from sklearn import datasets
sklearn.model_selectionライブラリ内のtrain_test_split関数を読み込みます
from sklearn.model_selection import train_test_split
データセット内のirisデータセットを読み込みます
iris = datasets.load_iris()
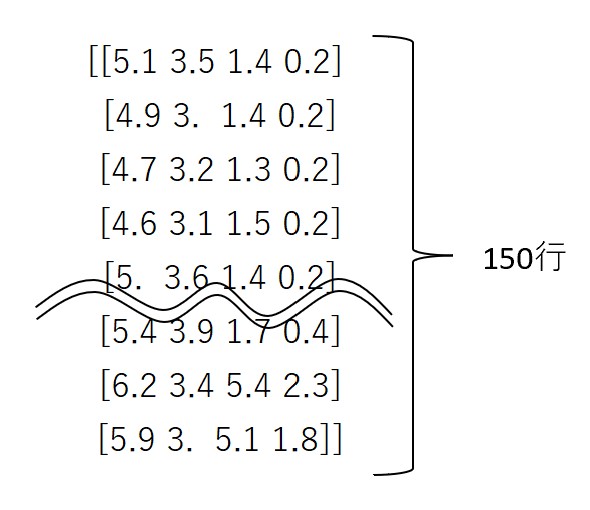
変数Xに正解ラベル以外の配列を代入します
X = iris.data
#このような150行4列の行列データです
yにXに対する正解ラベルの配列を代入します
y = iris.target
#このような150行の行列データです。
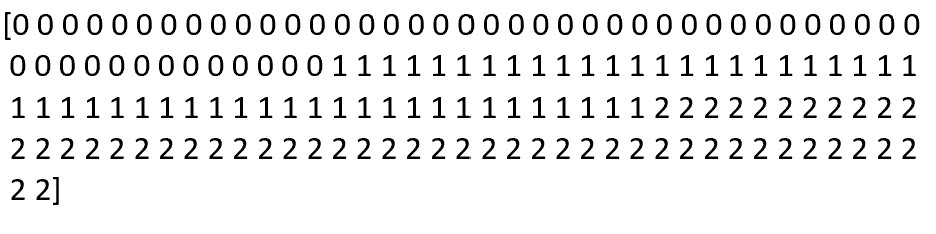
「X_train, X_test, y_train, y_test」にX,yデータを振り分けて格納します。test_size=0.2はテストデータの割合を指示します。ここでは20%と指示しています。random_state=0は省略可能ですが、省略するとテストデータが毎回ランダムで選ばれます。データセットが変わると精度も変わるので、通常指定しておきます。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
print (“X_train :”, X_train.shape)
print (“y_train :”, y_train.shape)
print (“X_test :”, X_test.shape)
print (“y_test :”, y_test.shape)
訓練データとテストデータのサイズを表示します。150行4列のデータが120行4列と30行4列に振り分けられました。
X_train : (120, 4)
y_train : (120,)
X_test : (30, 4)
y_test : (30,)
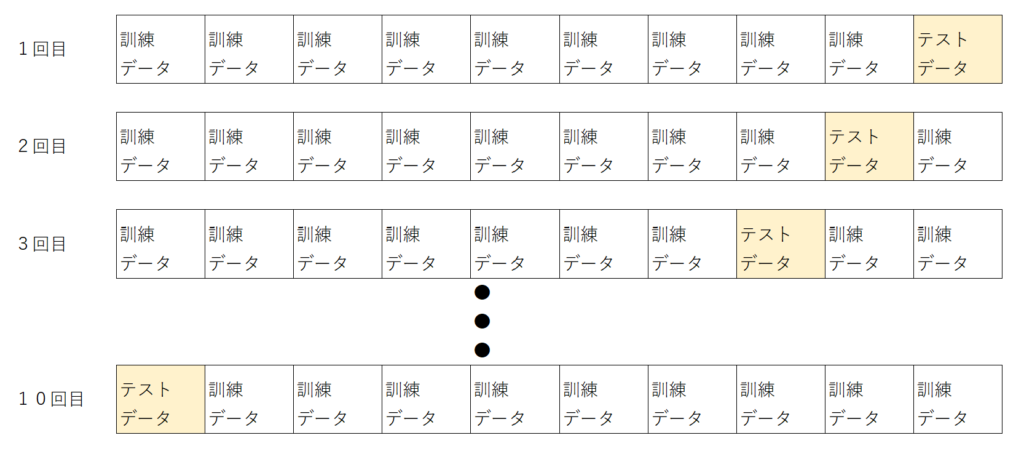
k-分割交差検証(クロスバリデーション)で少ないデータでもモデルの精度を上げる
k-分割交差検証では、データをk分割し、そのうち一つを検証データ、残り(k-1)をテストデータとして使用します。その後、テストデータとして使用する変えることでk個のモデルによる性能評価が可能です。
そのため、データ数が少ない場合(100個以下の場合)でもモデルの精度をあげることが可能です。
以下にクロスバリデーションのイメージを示します。クロスバリデーションしない場合は1回の学習で終了しますが、クロスバリデーションを使用することで10回の学習が可能になります。