ここで学習すること
非線形のサポートベクターマシンを使った分類の仕方を学習します。
pythonに格納されているirisデータを用いて実際に線形SVMで分類を行います。
サポートベクターマシンでは線形の分類しかできませんでした。これに対し、非線形サポートベクターマシンは非線形の分類が可能です。非線形SVMはscikit-learnのsvmサブモジュールにあるSVC()を使用します。
pythonに格納されているirisデータをサンプルに使用します。irisデータとは150個のアヤメ(花の一種)のサンプルの「がく片の長さ」「がく片の幅」「花びらの長さ」「花びらの幅」の4つの説明変数と、3種の品種(目的変数)が格納されています。ここでは「がくの長さ」と「花びらの長さ」を使用します。
from sklearn.svm import SVC #非線形サポートベクターマシンのインポート
from sklearn import datasets #sklearnに保存されているデータセットのインポート
from sklearn.model_selection import train_test_split #データを分割するため、train_test_splitをインポート
from sklearn.datasets import make_gaussian_quantiles
import numpy as np #数値計算ライブラリのNumpyをインポート
import matplotlib.pyplot as plt #グラフ作成ライブラリのmatplotlib.pyplotのインポート
import matplotlib #データの描写ライブラリのmatplotlibのインポート
iris = datasets.load_iris()
irisデータ
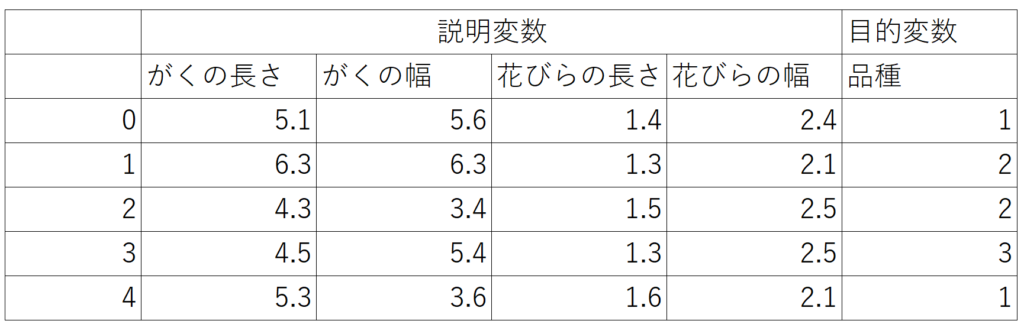
# irisの0列目(がくの長さ)と2列目(花びらの長さ)を変数Xに格納(行はすべて格納)
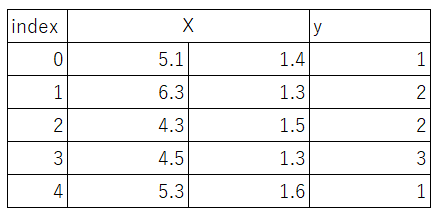
X = iris.data[:, [0, 2]]
# irisのクラスラベルを格納
y = iris.target
irisのデータセットがこのようになりました
#ここはホールドアウト法です。データを訓練データとテストデータに分割します。テストデータの割合を3割で指示しています。
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.3, random_state=42)
#非線形サポートベクターマシンのモデルを作成します
model = SVC()
#作成したモデルを使用して学習します。
model.fit(train_X, train_y)
#printのコマンドです
fig, (axL, axR) = plt.subplots(ncols=2, figsize=(10, 4))
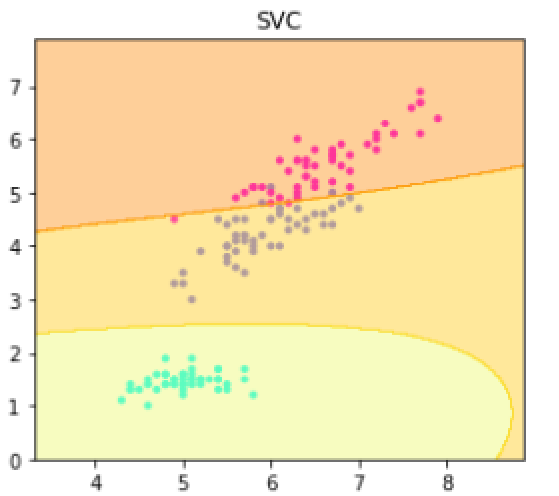
axL.scatter(X[:, 0], X[:, 1], c=y, marker=”.”,
cmap=matplotlib.cm.get_cmap(name=”cool”), alpha=1.0)
x1_min, x1_max = X[:, 0].min() – 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() – 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, 0.02),
np.arange(x2_min, x2_max, 0.02))
Z1 = model1.predict(np.array([xx1.ravel(), xx2.ravel()]).T).reshape(xx1.shape)
axL.contourf(xx1, xx2, Z1, alpha=0.4,cmap=matplotlib.cm.get_cmap(name=”Wistia”))
axL.set_title(“SVC”)
plt.show()