ここで学習すること
ランダムフォレストの特徴と実際のプログラム事例を学習します。
K近傍法はあるデータに着目したときにそのデータの近隣K個の平均や多数決でそのデータを予測するアルゴリズムです。
K=4なら緑に分類、K=11なら青に分類される。
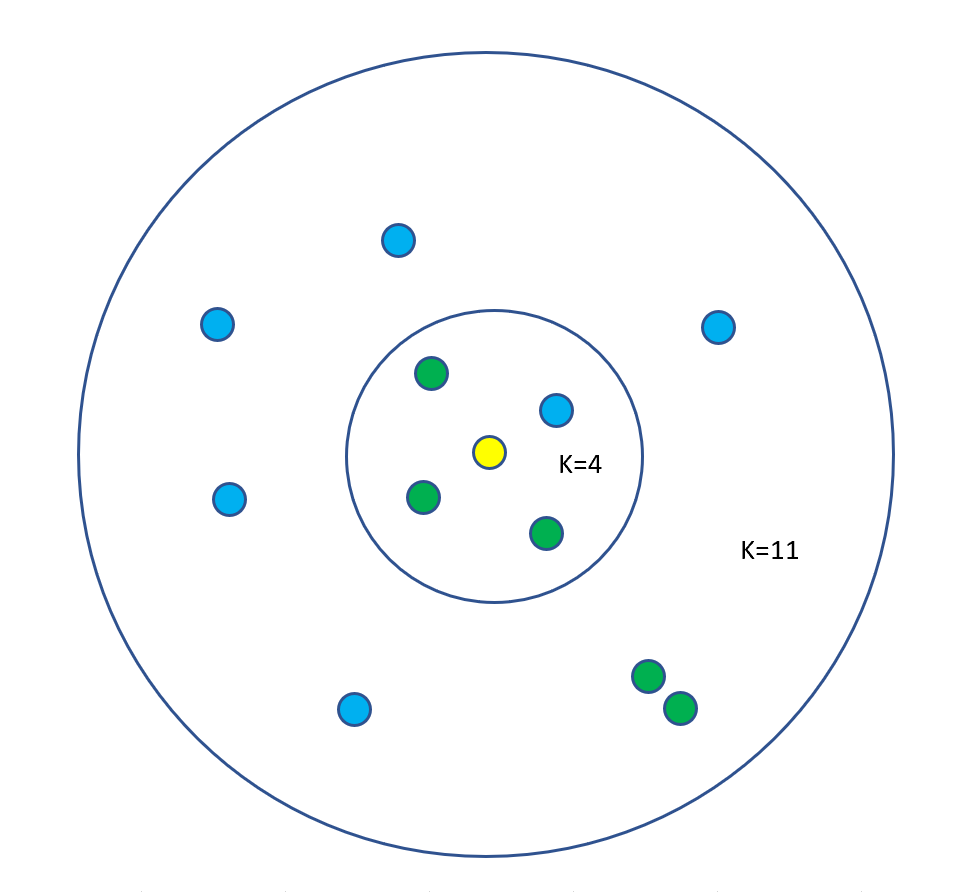
Kが小さいとノイズに弱くなり、Kが大きいと精度が下がります。
K近傍法はscikit-learnのサブモジュールneigborsにあるKNeighborsClassifier()を使います。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
irisデータを読み込みます。詳細は機械学習9|決定木を参照ください。
iris = datasets.load_iris()
X = iris.data[:, [0, 2]]
y = iris.target
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size0.2, random_state =42)
K近傍法のモデル作成します
model = KNeighborsClassifier()
model.fit(train_X, train_y)
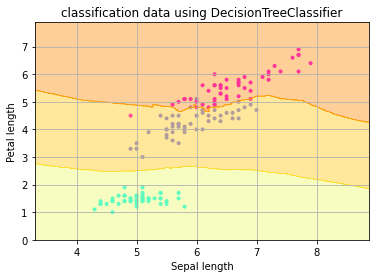
可視化プログラムです。詳細は機械学習9|決定木を参照ください。
plt.scatter(X[:, 0], X[:, 1], c=y, marker=”.”, cmap=matplotlib.cm.get_cmap(name=”cool”), alpha=1.0)
x1_min, x1_max = X[:, 0].min() – 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() – 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, 0.02), np.arange(x2_min, x2_max, 0.02))
Z = model.predict(np.array([xx1.ravel(), xx2.ravel()]).T).reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.3, cmap=mtplotlib.cm.get_cmap(name=’Wistia’))
plt.xlabel(‘sepal’)
plt.ylabel(‘petal’)
plt.grin(True)
plt.show
=>