ここで学習すること
ロジスティック回帰を用いた分類の仕方を学習します。
ロジスティック回帰は、直線で分類できるデータの境界線を学習によって見つけ、分類する手法です。境界が直線になるので、二項分類などクラスが少ないデータに使用されます。
ロジスティック回帰には以下の決定があります。
・線形分離可能でないと分類ができない
・⾼次元の疎なデータ(0が多いデータ)には適さない
・訓練データから学習した境界線がデータの近くを通るため、汎化能力が低い
ロジスティック回帰モデルはscikit-learnライブラリのlinear_modelサブモジュール内のLogisticRegression()で作成します。
基本的には「機械学習3|scikit-learn、LinarRegressionを用いて線形回帰モデルを作成する」で解説したホールドアウト法を用いた線形回帰モデルの作成と同じプログラムです。
ただし、使用するサンプルデータの前処理が異なるのでここから解説します。
データの前処理
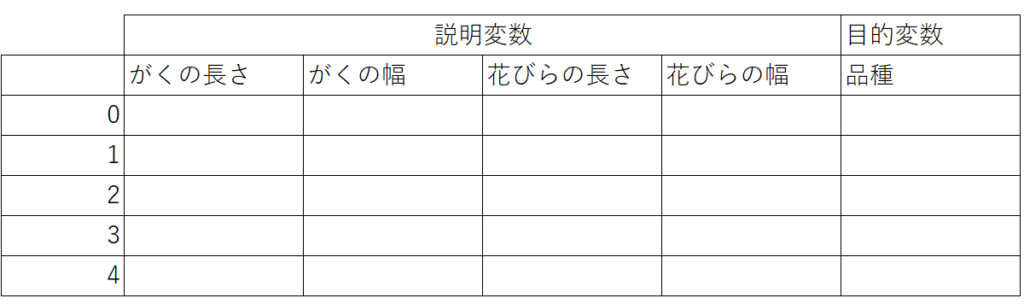
pythonに格納されているirisデータをサンプルに使用します。irisデータとは150個のアヤメ(花の一種)のサンプルの「がく片の長さ」「がく片の幅」「花びらの長さ」「花びらの幅」の4つの説明変数と、3種の品種(目的変数)が格納されています。ここでは「がくの長さ」と「花びらの長さ」を使用します。
# scikit-learnライブラリのdatasetsモジュールのimport
from sklearn import datasets
import numpy as np
# irisデータを取得
iris = datasets.load_iris()
# irisの0列目(がくの長さ)と2列目(花びらの長さ)を変数Xに格納(行はすべて格納)
X = iris.data[:, [0, 2]]
# irisのクラスラベルを格納
y = iris.target
irisデータ
ロジスティック回帰モデルの作成 model = LogisticRegression()
#ここはホールドアウト法です。データを訓練データとテストデータに分割します。テストデータの割合を3割で指示しています。
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.3, random_state=42)
#ロジスティック回帰モデルを作成します
model = LogisticRegression()
#訓練データ(train_X,train_y)を使ってモデルに学習させます
model.fit(train_X, train_y)
#テストデータ(test_X)を用いて予測値(y_predict)を予測します。
y_predict = model.predict(test_X)
print(y_predict.shape)
print(y_predict)
=>
(45,) #目的変数は45行の行列です
[1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1 0 0 0 2 1 1 0 0]
print(test_X.shape)
print(test_X)
=>
(45, 2) #説明変数は45行2列の行列です
[[6.1 4.7]
[5.7 1.7]
[7.7 6.9]
[6. 4.5]
[6.8 4.8]
[5.4 1.5]
[5.6 3.6]
[6.9 5.1]
[6.2 4.5]
[5.8 3.9]
[6.5 5.1]
[4.8 1.4]
[5.5 1.3]
[4.9 1.5]
[5.1 1.5]
[6.3 4.7]
[6.5 5.8]
[5.6 3.9]
[5.7 4.5]
[6.4 5.6]
[4.7 1.6]
[6.1 4.9]
[5. 1.6]
[6.4 5.6]
[7.9 6.4]
[6.7 5.2]
[6.7 5.8]
[6.8 5.9]
[4.8 1.4]
[4.8 1.6]
[4.6 1. ]
[5.7 1.5]
[6.7 4.4]
[4.8 1.6]
[4.4 1.3]
[6.3 5. ]
[6.4 4.5]
[5.2 1.5]
[5. 1.4]
[5.2 1.5]
[5.8 5.1]
[6. 4.5]
[6.7 4.7]
[5.4 1.3]
[5.4 1.5]]
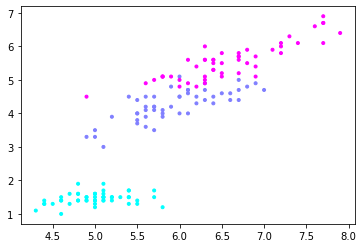
# .scatterで散布図を作成します。横軸に目的変数の第1引数(1列目)、縦軸に目的変数の第2引数(2列目)をプロットします。 マーカーサイズはy、マーカー種類は・、マーカー色はcoolの可変を指定します。
plt.scatter(X[:, 0], X[:, 1], c=y, marker=”.”, cmap=matplotlib.cm.get_cmap(name=”cool”), alpha=1.0)
plt.show()
=>