

教師なし学習にはクラスタリングと主成分分析があります。
クラスタリング
クラスタリングはデータを塊に分類することです。
クラスタリングのひとつにK-means法があります。K-means法ではクラスの重心をデータから学習し、重心をクラスタリングに使用します。K-means法では人がクラスターの個数を決めます。
クラスターの数を自動で決める方法に階層的という手法があります。これは多くの計算量が必要となるため、データ数が多い時には適さないことがあります。
主成分分析
主成分分析はデータの次元数を削減する場合に使う手法です。例えば、3次元のデータを2次元に減らすことを言います。
例えば、住宅価格には地域、広さ、商業施設の数等、様々なことが影響します。主成分分析ではこのような様々なデータと住宅価格の関係を1つのグラフで表せます。
ユークリッド距離
2次元空間の座標x(x1,x2)とy(y1,y2)の距離は√(x1-y1)^2+(x2-y2)^2で求められます。想像は難しいですが、n次元空間の距離はこれと同様に√(x1−y1)^2+(x2−y2)^2+…+(xn−yn)^2で求められます。
numpyを用いてユークリッド距離を求めることができます。
import numpy as np
x = np.array([1,2,3])
y= np.array([2,3,4])
print(np.linalg.norm(x-y))
=>
1.7320…(=√3)
コサイン類似度
ベクトルとは長さと方向から成ります。2つのベクトルの類似度は2つのベクトルが作る角度θの大きさと言えます。θが小さいほど、2つのベクトルは似ていることになります。
2つのベクトルa,bの内積
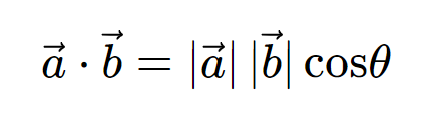
から以下が求まります。
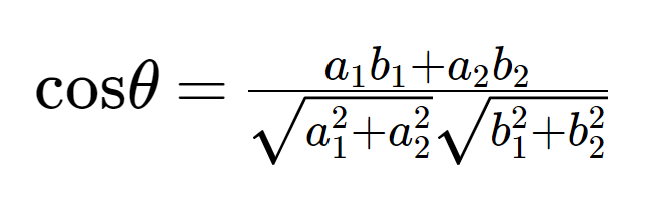
ベクトルの数が増えると以下となりこのcosθをコサイン類似度と言います。
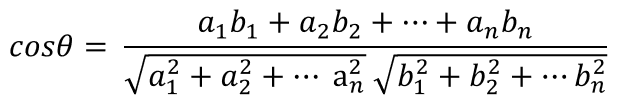
コサイン類似度はpythonでは以下を求めることができます。
import numpy as np
x = np.array([1,2,3])
y= np.array([2,3,4])
print(np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y)))
=>
0.9925833339709303


