

ここで学習すること
Nmpyで行列の計算する方法や、行列の要素を取り出す方法を学習します。
要素の合計を求める
num = [1, 2, 3, 4, 5, 6 ,7]
arr=np.array(num)
.sum()で要素の合計を求めます。
print(arr.sum())
=>28
下のエクセルファイル(filename.xlsx)を読み込みます。
エクセルファイルは.pyファイルと同じフォルダへ保存します。

import pandas as pd
df = pd.read_excel(‘filename.xlsx’)
import numpy as np
arr = np.array(df)
print(arr)
=>
[[ 2 4 2 3 6]
[ 1 4 9 4 8]
[12 5 43 76 9]
[ 0 98 3 7 8]
[ 2 7 67 5 3]]
print(arr.sum())
=>388
行、列それぞれの合計を求める
0軸の合計を計算する。

print(arr.sum(axis=0))
=>[ 17 118 124 95 34]
1軸の合計を計算する。

print(arr.sum(axis=1))
=>[ 17 26 145 116 84]
平均を求める
num = [1, 2, 3, 4, 5, 6 ,7]
.mean()で平均が求められます。
arr=np.array(num)
print(arr.mean())
=>4
行列の各軸の平均を求める
arr = np.array(df)
print(arr)
=>
[[ 2 4 2 3 6]
[ 1 4 9 4 8]
[12 5 43 76 9]
[ 0 98 3 7 8]
[ 2 7 67 5 3]]
.mean()で全要素の平均を求められます。
print(arr.mean())
15.52
.mean(axis=0)で0軸の平均を求められます。
print(arr.mean(axis=0))
[ 3.4 23.6 24.8 19. 6.8]
.mean(axis=1)で全要素の平均を求められます。
print(arr.mean(axis=1))
[ 3.4 23.6 24.8 19. 6.8]
分散を求める
先ほどの行列の分散を求めます
arr = np.array(df)
print(arr)
=>
[[ 2 4 2 3 6]
[ 1 4 9 4 8]
[12 5 43 76 9]
[ 0 98 3 7 8]
[ 2 7 67 5 3]]
.var()で分散が求められます。
print(arr.var())
656.0895999999999
.var(axis=0)で0軸の分散が求められます。
print(arr.var(axis=0))
[ 19.04 1385.04 671.36 814. 4.56]
.var(axis=1)で1軸の分散が求められます。
print(arr.var(axis=1))
[ 2.24 8.56 734. 1406.96 632.96]
MAX/MINを求める
先ほどの行列の分散を求めます
arr = np.array(df)
print(arr)
=>
[[ 2 4 2 3 6]
[ 1 4 9 4 8]
[12 5 43 76 9]
[ 0 98 3 7 8]
[ 2 7 67 5 3]]
.max()/.min()でMax/Min値が求められます。
print(arr.max())
98
.max(axis=0)で0軸のMax値が求められます。
print(arr.max(axis=0))
[2 1 5 0 2]
.min(axis=1)で1軸のMin値が求められます。
print(arr.nim(axis=1))
[2 1 5 0 2]
Max/Min値のindexを求める
argmax()/argmin()で行列のMax/Min値のindexが求められます。
あるデータの項目A(例:米国株価)が最大の時の項目B(例:日本株価)の値を求める時などに便利です。
先ほどの行列を使用します。
arr = np.array(df)
print(arr)
=>
[[ 2 4 2 3 6]
[ 1 4 9 4 8]
[12 5 43 76 9]
[ 0 98 3 7 8]
[ 2 7 67 5 3]]
0軸の行列のindex0(0列)の最大値(12)のindexを取得
max=arr.argmax(axis=0)[0]
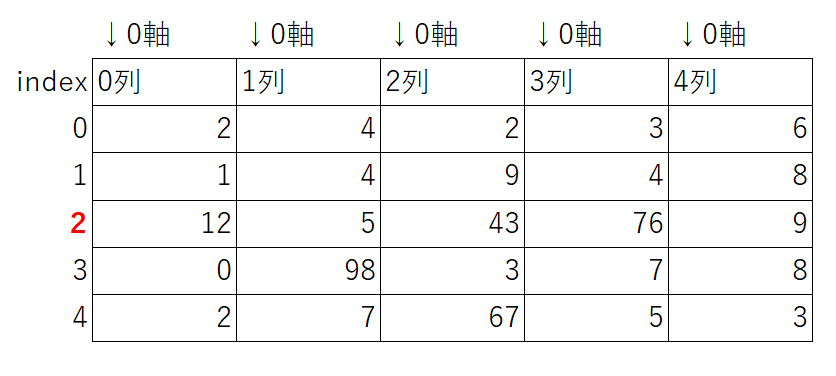
print(max)
=>2
1軸の行列のindex1(1列)の最大値(98)のindexを取得
max2=arr.argmax(axis=1)[2]
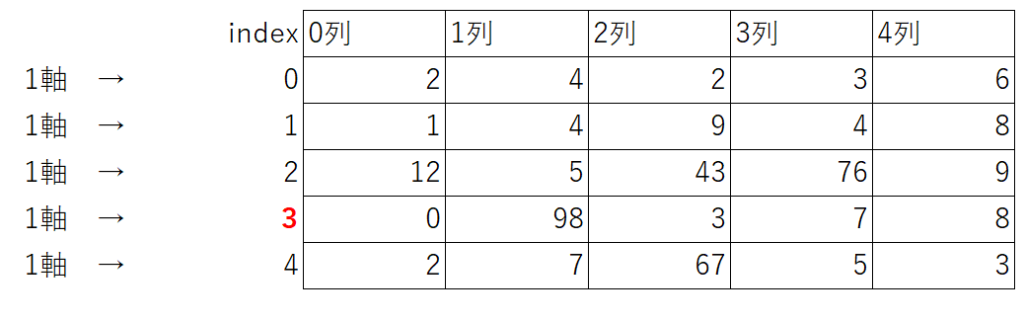
print(max2)
=>3
max=arr.argmax(axis=0)[0] #0軸の行列のindex0(0列)の最大値(12)のindexを取得
arr[max] #上記indexの行すべてを取得
print(arr[max])
[12 5 43 76 9]
ソートしたindexを取得する
先ほどの行列を使用します。
arr = np.array(df)
print(arr)
=>
[[ 2 4 2 3 6]
[ 1 4 9 4 8]
[12 5 43 76 9]
[ 0 98 3 7 8]
[ 2 7 67 5 3]]
0列目を小さい順に並べたときのindexを取得
sort=arr[:, 0].argsort()
.argsort()で要素を小さい順に並べた場合のindexを取得できます。
print(sort)
[3 1 0 4 2]
Top3を表示
print(sort[:3])
[3 1 0 ]


